Hash Tables
Hashing is a
technique used uniquely to identify a specific object from a group of similar
objects. For example in universities, each student is assigned a unique
identification number that can be used to retrieve information. In this case
the students has been hashed to a unique number.
Hashing
generally uses a system where an object will ne assigned with a specific key to
make searching far easier. Keys normally take the form of a simple array. In
hashing large keys are converted into small keys by using hash functions and
the values are then stored in a hash table.
a = hashfunc(key)
-> hashing
b = hash % array_size -> making the index
b = hash % array_size -> making the index
Hashing is
implemented in 2 steps:
1. An element is converted into an integer by using the hash function, then it is used as an index to store the original elements (goes into the hash table).
1. An element is converted into an integer by using the hash function, then it is used as an index to store the original elements (goes into the hash table).
2. The
element stored in the hash table can be retrieved by using a hashed key.
Hash
Function
A hash
function is any function that is used to map a data set of an arbitrary size to
a data set of a fixed size, which then goes into the hash table. The values
returned by a hash function are called hash values (or hash codes, or hash
sums, or hash).
Criteria of
a good hashing mechanism:
1. Ease to compute: Must not become an algorithm in itself
2. Uniform distribution: It should not result in clustering
3. Avoid collisions: can occur when pairs of elements are mapped to the same hash value
1. Ease to compute: Must not become an algorithm in itself
2. Uniform distribution: It should not result in clustering
3. Avoid collisions: can occur when pairs of elements are mapped to the same hash value
Binary
Tree
A binary
tree is a tree data structure where each node has a maximum of 2 child nodes.

·
Parent
= node above a child node
·
Children
= nodes below a parent node
·
Leaves
/ external = nodes with no children
·
Siblings
= nodes with the same parent

Full
Binary Tree
A full binary
tree is a binary tree in which each node has exactly 0 or 2 children.
Complete Binary
Tree
A complete binary tree is a binary tree which is completely filled with the possible exception of the bottom level, which is filled from left to right. A complete binary tree provides the best possible ration between the number of nodes and the height. The height h of a complete binary tree with N nodes is at most O(log N).
A complete binary tree is a binary tree which is completely filled with the possible exception of the bottom level, which is filled from left to right. A complete binary tree provides the best possible ration between the number of nodes and the height. The height h of a complete binary tree with N nodes is at most O(log N).
Trees are so
useful and frequently used because:
1. Trees reflects the structural relationship within the data
2. Trees shows the hierarchies
3. Trees provide an efficient insertion and searching
4. Trees are very flexible data
1. Trees reflects the structural relationship within the data
2. Trees shows the hierarchies
3. Trees provide an efficient insertion and searching
4. Trees are very flexible data
Traversals
Traversal
algorithms are divided into 2 kinds:
·
Depth-First
Traversal
·
Breadth-First
Traversal
There are 3
different types of depth-first traversals:
·
PreOrder
traversal – visit the parent first and then left and right children
·
InOrder
traversal – visit the left child, then the parent and the right child
·
PostOrder
traversal – visit the left child, then the right child then the parent

PreOrder =
8, 5, 9, 7, 1, 12, 2, 4, 11, 3
InOrder = 9, 5, 1, 7, 2, 12, 8, 4, 3, 11
PostOrder = 9, 1, 2, 12, 7, 5, 3, 11, 4, 8
LevelOrder = 8, 5, 4, 9, 7, 11, 1, 12, 3, 2
InOrder = 9, 5, 1, 7, 2, 12, 8, 4, 3, 11
PostOrder = 9, 1, 2, 12, 7, 5, 3, 11, 4, 8
LevelOrder = 8, 5, 4, 9, 7, 11, 1, 12, 3, 2
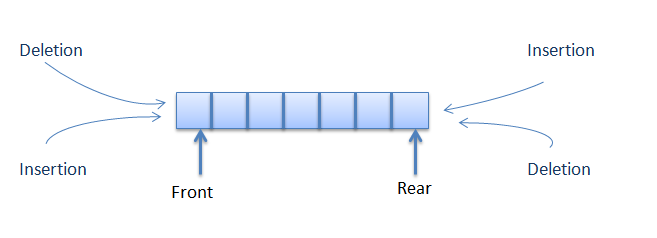
Insertion

Deletion

Things to
look for in deletion:
·
Is
not in a tree
·
Is
a leaf
·
Has
only 1 child
·
Has
2 child
Searching
Searching in a BST always starts at the root. To search the
data stored at the root will be compared to the key we are searching for (use “toSearch”).
If the node does not contain the key then it will check the next node.
Searching with BST has O(h) worst-case runtime complexity,
where h is the height of the tree while binary search will take at least O(log
n). Unfortunately, a binary search tree can degenerate to a linked list,
reducing the search time to O(n).